SPVNAS
SPVNAS: 基于点云-网格的稀疏卷积的3D神经网络结构搜索
论文信息
- Paper: [ECCV-2020] Searching Ecient 3D Architectures with Sparse Point-Voxel Convolution [1]
- Link: https://arxiv.org/pdf/2007.16100.pdf
背景梳理
-
为保证行驶安全性,自动驾驶汽车需要准确高效的理解3D场景。在一般场景下,激光雷达通常会扫描到数万个点,非欧地分布在整个空间中。我们可以将该过程类比于模拟图像转换为数字图像在更高的3D空间进行操作,如果按照图像离散化类似的分辨率进行网格化(例如长宽高为10^2数量级),数据量将大大增加。由于计算资源的限制,现存的3D视觉模型通常需要对点云数据进行低分辨率的网格化以及破坏性较大的下采样。对于较大物体来说,即使进行低分辨率网格化或激进的下采样,我们仍能够保留足够的信息对物体的类别进行判断,但对较小物体来说,低分辨率网格化将非常容易使其与周边物体混淆,导致模型输出错误的结果。
-
为解决这一问题,2019年末,MIT Han Lab发表论文Point-Voxel CNN for Efficient 3D Deep Learning[2],并提出新型点云处理框架 (Point-Voxel CNN,下称PVCNN),将点云处理领域的两类思路:基于栅格和直接处理点云的方法进行了结合。PVCNN可以快速、高效地进行3D点云数据,与此同时还能避免稀疏性带来的巨大的不规则数据访存开销,提高硬件效率。PVCNN这篇文章也成为了2019年NIPS的Spotlight文章。
-
虽然PVCNN在小物体和较小的区域理解中展现了强劲的性能,其在大规模室外场景上仍然无法高效部署。本文在作者之前工作的基础上,提出稀疏点云-栅格卷积(Sparse Point-Voxel Convolution ,下称SPVConv)方法。在增加的计算开销可忽略不计的前提下,使模型即使在户外大型场景中也能保留足够的细节信息。
主要贡献
- 作者设计了一个轻量级的3D模块SPVConv,它可以提高在小型物体上的性能,而在有限的硬件资源下,小型物体的分割是一个很有挑战性的问题。
- 作者设计了第一个3D场景理解中的AutoML框架:3D-NAS,可以给出在一定约束条件下的最佳3D模型。
- 截止在这篇文章截稿时,该方法在Semantic KITTI数据集的点云语义分割竞赛排行榜上排名第一(目前仍排名前四)。
方法
SPV-Conv
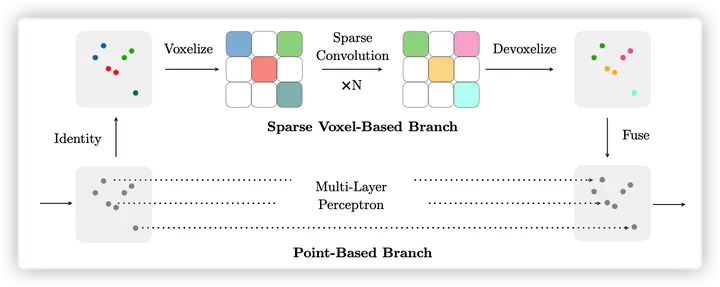
作者分析了Point-Voxel Convolution[2]以及Sparse Convolution[3]两种方法的瓶颈,并认为这两种方法都给模型带来了非常严重的信息损失。为克服这两个模型存在的缺点,作者提出了如下图所示的SPVCNN方法。

SPVCNN由[2]中栅格表示 (Volumetric Representation) 下聚合邻域信息的思路,转而在稀疏张量 (Sparse Tensor) 表示下利用三维稀疏卷积 (3D Sparse Convolution) 来处理邻域信息。而在基于点的分支中,作者直接在每个点上应用MLP来提取各个点的特征。然后将两个分支的输出与加法进行融合,以组合所提供的完整信息。与普通稀疏卷积相比,MLP层只需花费很少的计算开销(就mac而言为4%),但在信息流中引入了重要的细节。基于点的分支通过学习,主要用在小物体分割检测中。图中标红的点是该分支中最大特征范数前5%的点,而这些点几乎均位于小物体上,意味着该分支为小物体保留了大量信息。

3D-NAS
作者提出的3D-NAS将网络的设计流程分为两个阶段,以支持高效地设计3D场景理解网络。

在第一阶段中,作者的目的是训练一个包含其设计搜索空间(Design Space)中所有可能出现的子网络的一个超大网络模型。由于该超大规模网络数量可能过于巨大,因此尽可能降低计算复杂度。首先作者提出使用分布均匀采样(Distributed Uniform Sampling)和权值共享(Weight Sharing)方法来降低搜索空间规模。以上两个方法解决了网络搜索空间的可变通道数问题。除此之外,作者还需解决另一个更具挑战性的问题:可变网络深度支持。解决这一问题的方法是:深度渐进收缩(Progressive Depth Shrinkage)策略:作者将网络的训练过程进行分段,而对每一段网络的训练过程中,作者都允许一个范围来进行网络深度的选择。这种算法用可接受的复杂度支持了任意深度的子网络。 接下来是第二阶段的任务中作者借鉴了经典的遗传算法的思路(Evolutionary Search):在该过程中,作者将起始待选网络数量设计为n,每次迭代中作者选取表现最好的k个网络。下一次迭代的n个待选网络将由1/2的crossover和1/2的mutation组成。对于mutation操作,我们从topk待选网络中随机选择一个,将其结构按照一定的概率进行改变(网络深度,通道数量)。而对于crossover操作,我们从topk网络中随机选择两个进行组合得到新网络。
实验
作者在Semantic KITTI数据集上对其方法进行了评估,与同样基于3D的方法比较,SPVNAS方法在准确率,参数量,运算速度上都要胜过截止到该文章发布时的SOTA方法。(下图红色数字表示计算时间,蓝色数字表示该方法特有的预处理计算时间)




总结
本文提出了一种新型的3D点云分割方法SPVNAS,包含稀疏点云-栅格卷积以及3D-NAS两个主要部分。SPVconv通过结合基于网格的方法和基于Raw点的方法,有效保留了较小物体的信息,很大程度提升了较小物体的识别准确程度。除此之外,通过提出高效的3D-NAS AutoML结构,利用遗传算法思想,对该3D模型进行了充分的训练,使其在准确度,参数量,运算时间上都对当时的SOTA方法实现了超越。并在当时占据了Semantic KITTI数据集排行榜的第一名。
参考文献
[1]: Tang, H., Liu, Z., Zhao, S., Lin, Y., Lin, J., Wang, H., & Han, S. (2020, August). Searching efficient 3d architectures with sparse point-voxel convolution. In ECCV(2020)
[2]: Liu, Z., Tang, H., Lin, Y., Han, S.: Point-Voxel CNN for Ecient 3D Deep Learning. In: NeurIPS (2019)
[3]: Choy, C., Gwak, J., Savarese, S.: 4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks. In: CVPR (2019)
Zixing Lei
Master Student
My research interests include computer vision, embodied AI and multi-modality 3D understanding.